介绍csv文件的读写。
csv模块 csv.writer(csvfile) 1 2 3 4 5 6 7 8 9 10 import csv row = ['Symbol','Price','Date','Time','Change','Volume'] rows = [('AA', 39.48, '6/11/2007', '9:36am', -0.18, 181800), ('AIG', 71.38, '6/11/2007', '9:36am', -0.15, 195500), ('AXP', 62.58, '6/11/2007', '9:36am', -0.46, 935000), ] with open('name.csv','w') as csvfile: writer = csv.writer(csvfile,delimiter = '\t',lineterminator = '\n') #delimiter和lineterminator分别是分隔符,行结束符 writer.writerow(row) #写入单行 writer.writerows(rows) #写入多行
csv.reader(csvfile) 该函数接收一个可迭代对象,返回对象reader是一个生成器,不能直接用下标访问。可以用for循环和next()函数访问。
1 2 3 4 5 with open('name.csv','r') as csvfile: reader = csv.reader(csvfile,delimiter = '\t') #迭代器 rows = [row for row in reader] #用for循环访问: for row in rows: print(row)
输出结果为:
如果要读取csv文件的某列,可以看下面的例子
1 2 3 4 with open('name.csv','r') as csvfile: reader = csv.reader(csvfile,delimiter = '\t') #迭代器 column = [row[2] for row in reader] #用for循环访问: print(column)
输出结果为:
csv.DictReader(csvfile) 与csv.reader()函数相同,接收一个可迭代对象,返回一个生成器。不同之处是,返回的每个单元格放在字典的值中,字典的键就是这个单元格的列头。
1 2 3 4 5 with open('./name.csv','r') as f: reader = csv.DictReader(f,delimiter = '\t') rows = [row for row in reader] for row in rows: print(rows)
输出结果为:
如果要读取csv文件的某列,可以看下面的例子:
1 2 3 4 with open('./name.csv','r') as f: reader = csv.DictReader(f,delimiter = '\t') column = [row['Time'] for row in reader] print(column)
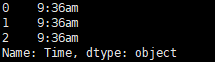
输出结果为:
csv.DictWriter(csvfile) pandas读写csv 也可以直接用pandas的函数read_csv()来读取csv文件的列。
1 2 3 4 import pandas as pd f = pd.read_csv('name.csv',delimiter = '\t') time = f.Time print(time)
输出结果为:
参考链接
最后更新时间:2019-07-21 23:22:55