记录ACL2019对话系统相关的论文阅读笔记。包括任务型和闲聊式对话系统,对论文的思路和模型做简单介绍,值得反复精读的论文会单独开一篇博文来写。
ACL2019的会议列表链接:http://www.acl2019.org/EN/program.xhtml
《Memory Consolidation for Contextual Spoken Language Understanding with Dialogue Logistic Inference》
【链接】:https://arxiv.org/abs/1906.01788
【源码】:无
中科院自动化所发表的短论文。在多轮对话中,对话历史(context information)对回复(response)的生成有重要作用。任务型对话中的管道模型分为4个模块:NLU、对话状态追踪、对话策略学习 及NLG。对话状态追踪又包含任务:domain classification、intent detection和slot filling。domain classification和intent detection任务当做分类任务来处理,常采用SVM或深度神经网络的方法;slot filling任务被当做序列标注任务来处理,常采用BiLSTM+CRF模型。NLU能否充分利用context information,对这三个下游任务有很大影响。
为了更好的利用context information,本文提出了对话逻辑推断任务(DLI,dialog logic inference),任务定义为:将打乱顺序的多轮对话重新排序;输入之前的对话,从剩余的utterance candidates中选中下一句对话。NLU任务采用了所谓的memory network,其实就是采用多个encoder对context information进行编码,再用attention机制或别的方法得到context information总的向量化表示。本文联合训练DLI任务和NLU任务,通过两个任务共享encoder和memory retrieve模块,来让NLU任务更好地利用context information。其实是得到context information更合理的向量化表示,来作为下游domain classification、intent detection和slot filling任务的输入。
论文提出的将打乱顺序的对话重新排序的DLI任务,可以进一步深入,将句子切分为几段打乱顺序再重新排序;可以应用到闲聊式对话系统中。
《Dialogue Natural Language Inference》
【链接】:https://arxiv.org/abs/1811.00671
【代码】:无
【数据集】:https://wellecks.github.io/dialogue_nli/
加利福尼亚大学、Facebook AI Lab发表的论文。核心是提出用NLI(natural language inference)任务来提高persona-based dialog system的一致性。这里就要先搞清楚NLI任务和一致性问题两个概念。
先从问题出发,所谓对话的一致性问题。可以分为两类:
logical contradiction,逻辑矛盾。比如同一个人的两句话:”我有一只狗”,”我没养过狗”。就是逻辑矛盾的。
比较模糊的非逻辑矛盾。同一个人不可能说出的两句话:“我从来不运动”,“我去篮球了”。就是这种非逻辑矛盾。真香警告。
至于persona一致性问题,就是回复的utterance不能与说话人的persona矛盾,也不能与之前的回复有矛盾。
具体介绍NLI任务。这其实是一个分类问题。论文公开了一个自己标注的NLI数据集。
- 训练阶段:训练集形式是 {$(s_1,s_2)$,label },对应labels $\in$(一致、无关、矛盾)。
- 在test阶段,给定一个句子对(句子1,句子2)来判断对应的label。
论文的最终目的是通过NLI任务训练的模型来提高persona dialog system的一致性。这是如何来实现的呢?对于一个dialog system,给定对话历史$(u_1,u_2,…,u_t)$ 及说话人的persona文本描述$(p_1,p_2,…,p_n)$,从response candidates$(y_1,y_2,…,y_m)$中选择一个$u_{t+1}$(如何生成多个responses不是这篇论文要解决的)。
用NLI任务的模型来预测$(y_i,u_j),(y_i,p_k)其中:i\in [1,m],j\in [1,t],k \in [1,n]$对应的label,如果句子之间是矛盾的,则添加惩罚项。从而得到一致性最好的utterance作为response。
《ReCoSa: Detecting the Relevant Contexts with Self-Attention for Multi-turn Dialogue Generation》
【链接】:https://arxiv.org/abs/1907.05339
【数据集】:English Ubuntu dialogue corpus
【代码】:https://github.com/zhanghainan/ReCoSa
中科院发表的论文。
在多轮对话中,生成response时,对话历史中最相关的部分起着重要的作用。论文要解决的问题:如何更准确地找到并利用relevant context来生成response。
多轮对话中广泛使用的HRED模型,[(Serban et al.,2016;,Sordoni et al., 2015]无差别地利用context information,忽略了relevant context。虽然有利用relevant context的相关工作,但这些工作都有各自的问题。[Tian et al., 2017]提出计算context 与post之间的cosine similarity来衡量context relevance,其假设是context与response之间的relevance等价于post与response之间的relevance,这个假设是站不住脚的。[Xing et al., 2018]向HRED模型引入了attention机制,但attention机制定位relevant context时会产生偏差,因为基于RNN的attention机制倾向于最靠近的context(close context)。论文提出了自己的解决办法,用self-attention机制来衡量context于response之间的relevance。self-attention机制的优点是可以有效捕捉到长距离的依赖关系。
模型分为三个部分:
context包含N轮对话: ${s_1,s_2,…,s_N}$其中,$s_i = {x_1,x_2,…,x_M}$,M为句子长度。
response为$Y = {y_1,y_2,…,y_M}$
- context representation encoder:
将context encode为vector。- word-level encoder:
用LSTM对sentence编码,将LSTM最后一个时间步的hidden state作为sentence representation: $h^{s_i}$;
由于self-attention机制不能区分word位置信息,还需要添加position embedding: $p^{s_i}$,
把两个向量做concatenate操作,得到总得sentence representation:$(h^{s_i},p^{s_i})$。
对于context中的N个句子有${(h^{s_1},p^{s_1}),…,(h^{s_N},p^{s_N})}$ - context self-attention:
采用multi-head self-attention机制,将${(h^{s_1},p^{s_1}),…,(h^{s_N},p^{s_N})}$经过不同的线性变换作为query、keys、values matrix,由N个sentence representation得到总的context representation $O_s$。
- word-level encoder:
- response representation encoder
同样用multi-head self-attention机制,将response的word embedding及position embedding ${(w_1,p_1),…,(w_{t-1},p_{t-1})}$经过不同的线性变换作为query、keys、values matrix,得到response representation $O_r$。- 在train阶段
采用mask操作,在时间步t对于word $y_t$,mask掉${y_t,y_{t+1},…,y_M}$,只保留${y_1,y_2,…,y_{t-1}}$来计算response representation。 - 在infer阶段
在生成response的时间步t,将生成的response ${g_1,…,g_{t-1}}$,来作为response representation。
- 在train阶段
- context-response attention decoder
采用multi-head self-attention机制,将context attention representation $O_s$作为keys、values matrix,将response hidden representation $O_r$作为query matrix。得到输出$O_d$.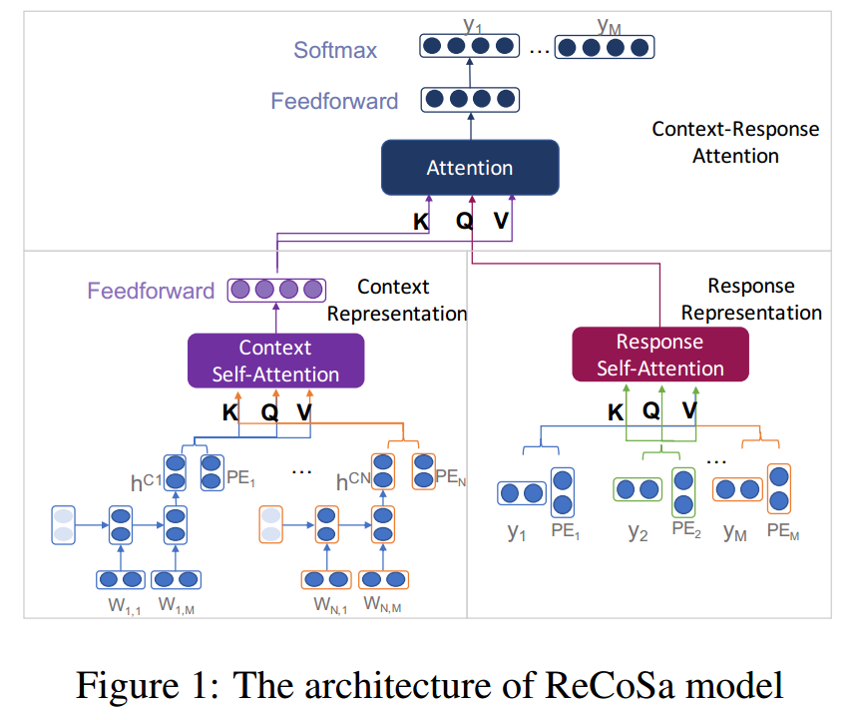 模型框架图
模型框架图
《Persuasion for Good: Towards a Personalized Persuasive Dialogue System for Social Good》
【链接】:https://arxiv.org/abs/1906.06725
【代码、数据集】:https://gitlab.com/ucdavisnlp/persuasionforgood/tree/master
浙江大学、加利福尼亚大学发表。获得ACL2019 best paper提名。
论文的主要贡献是公开了一个包含说话人个人信息的劝说数据集,在子集上标注了十种不同的劝说策略。并训练了用于分类不同劝说策略的分类器。
《Do Neural Dialog Systems Use the Conversation History Effectively? An Empirical Study》
【链接】:https://arxiv.org/abs/1906.01603
【代码】:https://github.com/chinnadhurai/ParlAI/
论文获得ACL2019 best short paper提名。
论文的研究点是:生成式对话系统是否有效利用或正确理解了对话历史?论文通过向对话历史中引入不同类型的扰动,来研究生成式对话系统生成回复的困惑度变化。这个方法的一个前提是如果生成式对话系统对某种信息的扰动不敏感,那么它没有有效利用这种信息。
论文在比较了三种模型。
- 基于LSTM的seq2seq模型。
- 基于LSTM的seq2seq模型 + attention机制。
- 基于transformer的seq2seq模型。
论文在四个多轮对话数据集上进行实验。
- bAbI dialog。(Bordes and Weston, 2016)
- Persona Chat。(Zhang et al., 2018)
- Dailydialog。 (Li et al., 2017)
- MutualFriends。(He et al., 2017)
论文向对话历史引入了不同的扰动。
- 句子级别的扰动:
- 随机打乱对话历史中句子的顺序。
- 倒序对话历史中句子的顺序。
- 随机去掉对话历史中特定的句子。
- 对话历史中有n个句子,只保留最近的k个句子$(k \le n)$。
- 词级别的扰动:
- 随机打乱一个句子中词的顺序。
- 倒序一个句子中词的顺序。
- 随机去掉对话历史中30%的词。
- 去掉所有的名词。
- 去掉所有的动词。
