【来源】:ARXIV 2019
【链接】:https://arxiv.org/abs/1903.12457v3
【代码、数据集】:https://github.com/THUDM/KOBE
清华大学和阿里巴巴发表的论文。论文的研究内容是给定商品名称,商品的属性特征和外部知识库,自动生成商品的描述。
数据集描述
论文在淘宝收集了一个真实的商品描述数据集,包含了212,9187个商品名称和描述。数据集是公开的,下载地址为:https://tianchi.aliyun.com/dataset/dataDetail?dataId=9717
任务定义
给定商品名称$x = \{x_1,…,x_n\}$,要求生成个性化的、富有信息的商品描述$y = \{y_1,…,y_m\}$。引入两个附加信息:商品属性 和 外部知识:
- Attributes
每个商品名称$x$对应$l$个属性$a = \{a_1,…,a_l\}$。论文中包含两种属性,商品的某个方面(如质量、外观等)和用户类型(反映用户的兴趣)。 - Knowledge
论文采用一个大规模的中文知识图谱CN-DBpedia作为外部knowledge。CN-DBpedia包含大量命名实体$V$索引的原始文本条目$W$。每个条目包含一个命名实体$v \in V$作为key,对应一个knowledge句子 $w = \{w_1,…,w_u\} \in W$作为value。
最终的任务定义为:给定商品名称$x$、商品属性$a$和相关的knowledge $w$,要求生成个性化的,信息量丰富的回复$y$。
模型结构
模型采用了基于Transformer的encoder-decoder框架,结合了两个模块:Attribute Fusion和knowledge Incorporation。
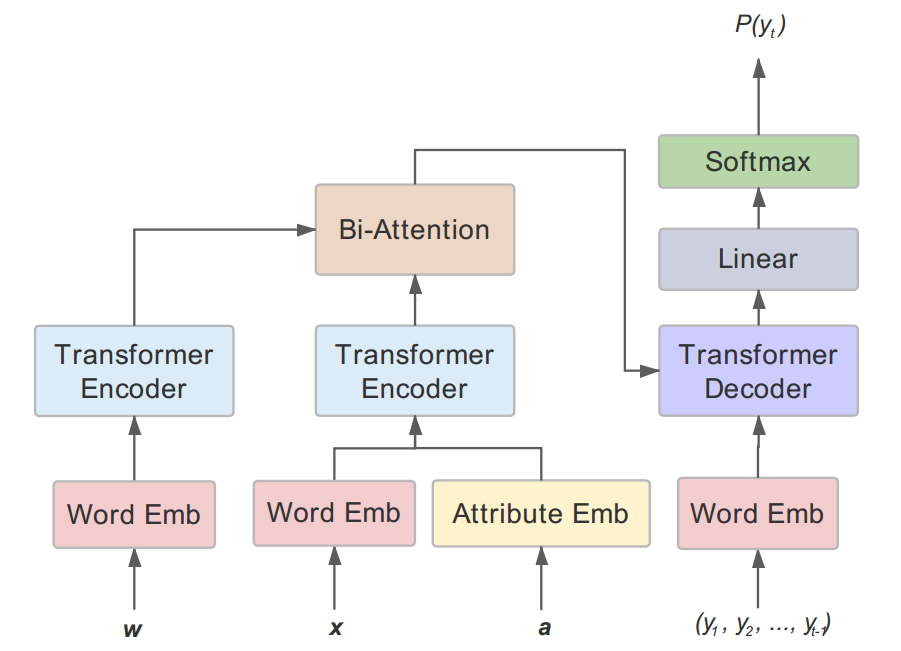
encoder-decoder框架
Transformer是完全基于self-attention机制 和 前馈神经网络(FFN,feed-forward neural network)的。
- encoder
对于输入$x = \{x_1,…,x_n\}$,先经过embedding层得到word embedding representation $e = \{e_1,…,e_n\}$,连同position embedding一起,作为encoder layers的输入,得到context representation $h = \{h_1,…,h_n\}$。
在embedding层之上,encoder layers由完全相同的6层堆叠组成,每层transformer包括multi-head self-attention和FFN两部分。- attention机制
attention机制根据queries $Q$和keys $K$计算在values $V$上的分布,进而得到attention的输出。$$C = \alpha V$$ $$\alpha = softmax(f(Q,K))$$其中$C$表示attention的输出,$\alpha$表示attention的分布,$f$表示计算attention分数的函数。 - uni-head attention
对于单头attention,queries $Q$,keys $K$和values $V$分别是输入context $e$的线性转换。即$Q = W_Qe$, $K = W_Ke$ 和 $V = W_Ve$。此时,uni-head attention可以表示为 $$C_{self} = softmax(\frac{QK^T}{\sqrt{d_k}})V$$ 其中$d_k$表示输入$e$的维度。 - multi-head attention
对于多头attention,将$C^i_{self}, i\in \{1,2,…,c\}$连接起来,作为FFN的输入。其中$c$表示heads的数量。
再经过前馈神经网络(FFN),FFN的函数表示为:$$FFN(z) = W_2(Relu(W_1z + b_1)) + b_2$$
- attention机制
- decoder
与encoder类似,decoder也是由完全相同的6层堆叠而成的,每层包含multi-head attention和FFN两部分。不同于encoder的”self-attenion”,decoder的multi-head attention是“context attention”。queries $Q$是decoder state的线性转换,keys $K$和values $V$是context states $h = \{h_1,…,h_n\}$的线性转换。 - Training
模型的目标是最大化似然函数。模型的目标函数是:$$P(y|x) = \prod_{t=1}^m P(y_t|y_{<t},x)\tag{1}$$
Attribute Fusion模块
商品的属性$a = \{a_1,a_2\}$,包含商品方面 和 用户类型两个属性。先经过embedding层得到attribute representation $\{e_{a_1},e_{a_2}\}$,再做attribute average得到总的attribute representation $e_{attr}$: $$e_{attr} = \frac{1}{2}\sum_{i=1}^2e_{a_i}$$ 如何有效结合$e_{attr}$呢?在基于RNN的模型中,方法比较多,比如:用$e_{attr}$来attend context representation,或着作为decoder隐藏状态更新的输入等。但本文中的模型是基于Transformer的,直接将attribute embedding $e_{attr}$与word embedding $e_i$相加,来结合商品的属性信息。如Fig.2所示。
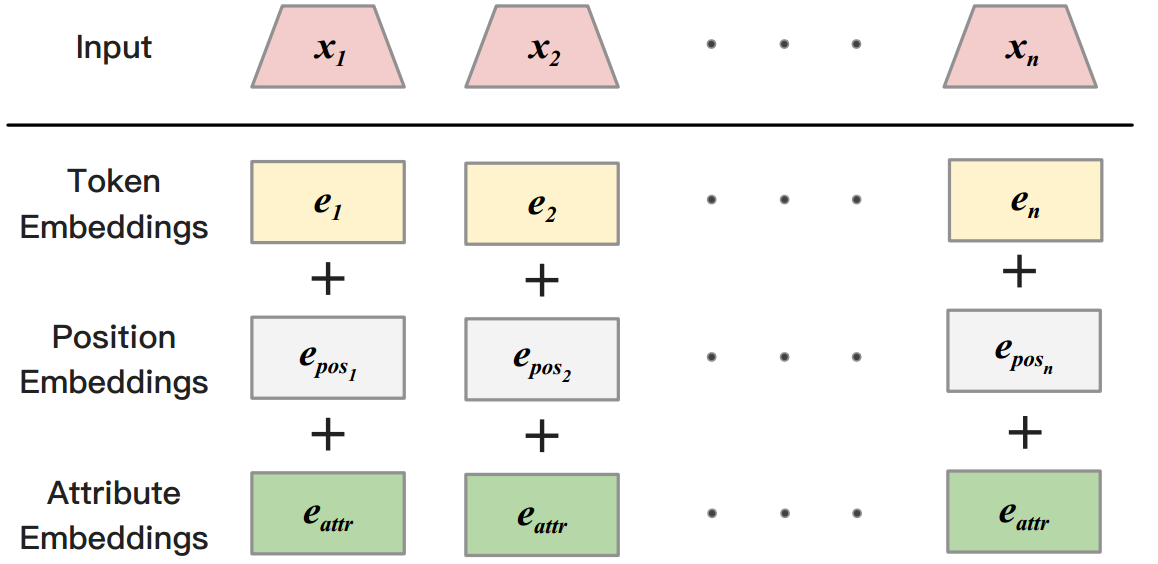
此时,公式(1)中的目标函数变为$$ P(y|x,a) = \prod_{t=1}^m P(y_t|y_{<t},x,a)$$
Knowledge Incorporation
knowledge incorporation包括三个部分,knowledge检索,knowledge编码,和knowledge结合。
- knowledge retrieval
给定商品名称$x = \{x_1,…,x_n\}$,对于每个word $x_i$匹配对应的命名实体$v_i \in V$。再根据命名实体$v_i$,从$W$中检索对应的knowledge $w_i$。对于每个商品,最多抽取5个匹配的knowledge,再用分隔符 “”连接起来。 - knowledge encoding
类似于$x = \{x_1,…,x_n\}$通过encoder编码得到context representation $h = \{h_1,….,h_n\}$,将检索到的knowledge经过一个基于Transformer的knowledge encoder得到knowledge representation $u$。 - knowledge combination
用BiDAF(bidirectional attention flow)来结合context representation $h$和knowledge representation $u$。BiDAF计算两个方向的attention:title-to-knowledge attention和knowledge-to-context attention。- 相似度矩阵S
先计算一个context representation $h \in R^{n \times d}$和knowledge representation $u \in R^{u \times d}$之间的相似度矩阵$S \in R^{n\times u}$。其中$S_{ij}$衡量第i个title word和第j个knowledge word之间的相似度。$$S_{ij} = \alpha(h_i,u_j) \in R$$ 其中$\alpha()$是计算两个向量之间相似度的函数。 $$\alpha(h,u) = W_s^T[h;u;h \cdot u], W_s\in R^{3d}$$ - title-to-knowledge attention
表明了对于每个title word,哪个knowledge word是最相关的。
$a_i \in R^u$表示对于第i个title word,在所有knowledge words上的attention权重分布。$$a_i = softmax(S_{i:}) \in R^u$$ 其中,$S_{i:}$表示相似度矩阵$S \in R^{n\times u}$的第i个行向量。对于所有的$i$,$a_i$满足:$$\sum_ja_{ij} = 1$$ 对于第i个title word,attended knowledge vector为:$$\widetilde{u_i} = \sum_ja_{ij}u_j$$ 则对于所有的title words $\{x_1,…,x_n\}$,有$\widetilde{u} \in R^{n \times d}$ - knowledge-to-title attention
表明了对于每个knowledge word,哪个title word是最相似的。
计算在所有title words上的attention权重分布:$$b = softmax(max(S_{i:}))$$ 则attended title vector为$$\widetilde{h} = \sum_{k}b_kh_k$$ 把$\widetilde{h}$在列上复制n次,得到$\widetilde{h} \in R^{n\times d}$。 - 输出融合
做一个简单的连接操作,得到组合representation: $[h;\widetilde{u};h\circ \widetilde{u};h\circ \widetilde{h}] \in R^{4d \times n}$
- 相似度矩阵S
参考链接
- BiDAF(bidirectional attention flow)可以参考:
- 中文知识图谱
CN-DBpedia可以参考:
