【来源】:NAACL2019
【链接】:https://www.aclweb.org/anthology/N19-1284/
【代码】:https://github.com/hao-cheng/dynamic_speaker_model
这篇论文是由华盛顿大学发表的。
个性化对话系统的研究现状
近几年来,基于用户画像(personal information)来生成个性化的回复已经成为对话系统领域的一个研究热点。为什么要将persona结合到对话系统模型中呢?目的是提高生成回复的一致性,来获取用户信任,让用户在对话中更投入。生成回复的一致性具体指什么呢?举个例子,你问对话系统“你的职业是什么?”,它可能回答是出租车司机;当你再次问这个问题时,它又可能回答是老师。给定对话系统一个用户画像(persona),基于这个persona来生成回复,就可以提高生成回复的一致性,避免出现这种问题。基于persona来生成个性化的回复,也是对话系统可以通过图灵测试的必要条件。
现有的工作中,将persona结合到对话系统模型中的思路有两种。
- 学习一个潜在的向量user embedding(或user representation)来潜在地表示用户画像,再基于这个user embedding来生成个性化的回复。这样做的一个原因是现有的对话语料中没有相应的用户画像文本信息,随着个性化对话数据集Persona-Chat以及CONVAI2的提出,就有了第二种思路。
- 直接用键值对属性值信息或者是自由文本来明确地描述用户画像,再生成个性化的回复。
论文简介
这篇论文属于第一种思路,主要内容是用神经网络模型从对话历史中学习一个动态更新的user embedding。并且将学习到的user embedding用到了两个下游任务(对话话题分类、dialog acts分类)中来评估user embedding的学习效果。
论文中提到,学习一个动态更新的user embedding的动机有两个:
- 用户的对话反映了这个用户的对话意图、语言风格等特征。因此,可以从用户的对话中来学习user embedding来建模和表征用户的这些个性化特征。
- 随着对话的进行,用户的个人信息得到累积。因此,可以从对话中提炼和动态更新user embedding。
模型结构
如下图所示,模型包括三个部分:Latent Mode Analyzer,Speaker State Tracker,Speaker Language Predictor。
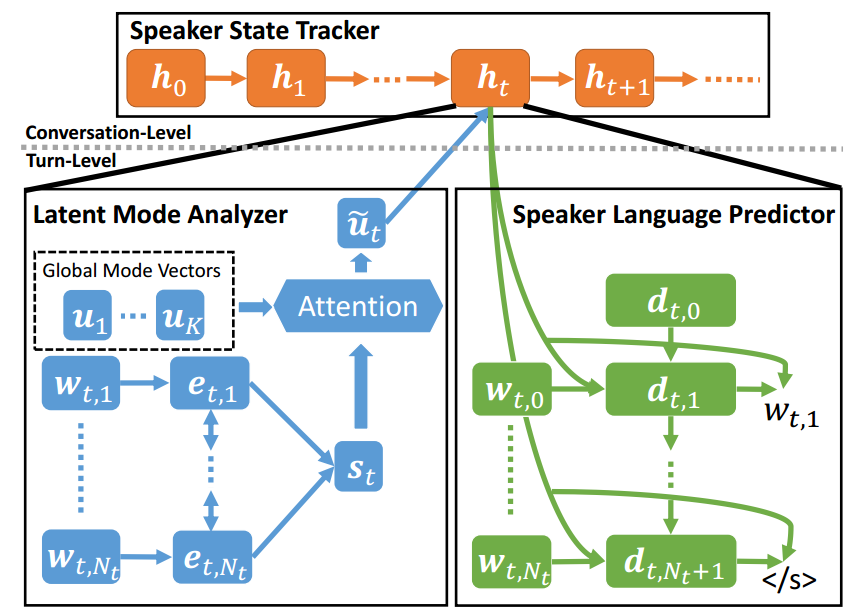
Latent Mode Analyzer
Latent Mode Analyzer的作用是从输入的单轮对话中学到一个 local speaker vector。采用了Bi-LSTM + Attention机制。
时间步t,输入为单轮对话$\lbrace{w_{t,1},w_{t,2},…,w_{t,{N_t}}\rbrace}$,经过embedding层后送入到Bi-LSTM层,将前向LSTM和后向LSTM的最后一个隐藏状态连接起来作为句子总的向量表示$s_t$: $$s_t=[e^F_{t,N_t},e^B_{t,1}]$$ 其中,$e^F_{t,N_t},e^B_{t,1}$分别表示前向LSTM和后向LSTM的最后一个隐藏状态。
接着,再使用attention机制。将句子的向量表示作为attention机制的query,将 $K$ 个全局的mode vectors $\lbrace{u_1,u_2,…,u_K\rbrace}$作为attention机制的keys和values。这$K$个mode vectors也是模型参数,可以看作是用户在不同方面的个性化特征。那么可以通过attention机制计算得到local speaker vector $\tilde{u_t}$ :$$\tilde{u_t} = \sum_{k=1}^Ka_{t,k}u_k$$ $$a_{t,k} = softmax(\beta_{t,k})$$ $$\beta_{t,k} = <Ps_t,Qu_k>$$ 其中$< , >$表示点乘操作。
Speaker State Tracker
Speaker State Tracker 的作用是动态更新speaker state vector。实质上是一个单向的LSTM。
在时间步t,根据当前的local speaker vector $\tilde{u_t}$ 和 上一个时间步的隐藏状态$h_{t-1}$来更新隐藏状态$h_t$。将$h_t$作为时间步t的speaker state vector。$$h_t = LSTM(\tilde{u_t},h_{t-1})$$
Speaker Language Predictor
Speaker Language Predictor的作用是促进前两个模块的参数学习,根据speaker state vector来重构句子$\lbrace{w_{t,1},w_{t,2},…,w_{t,{N_t}}}\rbrace$。
该模块实质上是一个条件语言模型,预测条件概率 $P(w_{t,n}|w_{t,<n})$。采用了单向的LSTM,LSTM的隐藏状态更新公式为:$$d_{t,n} = LSTM(R^I(w_{t,n-1},h_t),d_{t,n-1})$$ 其中$R^I()$是一个线性层。
则语言模型生成下一个词的条件概率为:$$P(w_{t,n}|w_{t,<n}) = softmax(VR^O(h_t,d_{t,n}))$$ 其中$R^O()$是一个线性层。
损失函数
模型最小化负对数似然函数来更新模型参数: $$L = -\sum_{t}\sum_{n}log P(w_{t,n}|w_{t,<n})$$
