【来源】AAAI2019
【链接】https://arxiv.org/pdf/1811.04604v1.pdf
【代码】未公布
这篇论文是北京大学于2019年初发表的。研究内容主要是将用户个性化信息(personalization)结合到端到端的任务型对话模型中,来调整回复的策略和语言风格,并消除歧义。
个性化对话系统的相关工作
最早探索个性化对话系统的研究工作是 Li Jiwei于16年发表的论文《A Persona-Based Neural Conversation Model》。这个工作的具体来说是,给chatbot agent赋予特定的人格来生成一致性的回复。另一个思路,我们更希望chatbot agent可以感知到用户的身份和偏好,来提供个性化的对话。
个性化的对话系统也是分为闲聊式对话和任务型对话。
- 个性化闲聊式对话的训练语料有Persona-Chat和在此基础上扩展得到的CONVAI2,另外还有Mazare et al.(2018)基于Reddit Corpus构建的个性化对话语料。
- 个性化的任务型对话系统的训练语料有personalized bAbI dialog corpus。
缺乏个性化的任务型对话系统的不足
只基于对话历史而未考虑个性化的任务型对话系统存在以下不足:
- 不能根据用户的身份和偏好来动态地调整语言风格。
- 缺乏根据用户的信息来动态调整对话策略的能力。
- 难以处理用户请求中的歧义项。比如:“contact”可以理解为“电话”,也可以理解为“社交媒体”。个性化模型可以学习到年轻人倾向于社交媒体,而老年人倾向于电话这一事实,从而消除歧义。
个性化任务型对话系统的研究动机就是解决上述问题。个性化的任务型对话与chatbot有所区别。个性化的chatbot研究倾向于赋予chatbot以特定的用户画像,来生成一致性的回复。而个性化的任务型对话更多的是感知到用户的身份和偏好,从而根据不同的用户身份来调整回复的语言风格和对话策略,从而提高对话效率和用户满意度。
End-to-End Memory Network
本文的个性化任务型对话模型是基于Memory Network的,因此对Memory Network做简单的介绍。Memory Network的相关工作有许多,本文中介绍的是发表在ICLR2017的《Learning end-to-end goal-oriented dialog》,这是基于检索的任务型对话。Memory Network包括了两个部分:context memory和next sentence prediction。
Memory Representation
memory中储存的是对话历史。在时间步t,对话历史为$t$句用户的对话$\lbrace{c_1^u,c_2^u,…,c_t^u}\rbrace$以及$t-1$句对话系统的回复$\lbrace{u_1^r,u_2^r,…,u_{t-1}^r}\rbrace$。直接采用了词袋方法,经过embedding层,将对话历史表示为向量。 $$m = (A\Phi(c_1^u),A\Phi(c_1^r),…,A\Phi(c_{t-1}^u),A\Phi(c_{t-1}^r))$$ 其中$\Phi(\cdot)$是one-hot向量表示,$A$是embedding table。
用同样的方法,将上一句话$c_t^u$编码为attention机制的的query:$$q = A\Phi(c_t^u)$$
Memory Operation
采用attention机制对context memory进行读取。计算方式如下:$$o = R\sum_i\alpha_im_i$$ $$\alpha_i = softmax(q^\top m_i)$$ 其中$R$是线性层的权重矩阵。
多跳机制
将query按下式进行更新,再采用attention机制对context memory进行读取。$$q_2 = q + o$$
next sentence prediction
设有C个候选句子$y_i$。先将候选句子进行向量化表示: $$r_i = W\Phi(y_i)$$ 其中$W$是另一个embedding table。
则最终的预测概率分布为:$$\hat{r} = softmax({q_{N+1}}^\top r_1,…,{q_{N+1}}^\top r_C)$$
模型结构
模型包括profile model和preference model。profile model将用户的个性化信息结合到模型中。preference model建模用户信息与知识库之间的联系,来消除歧义。
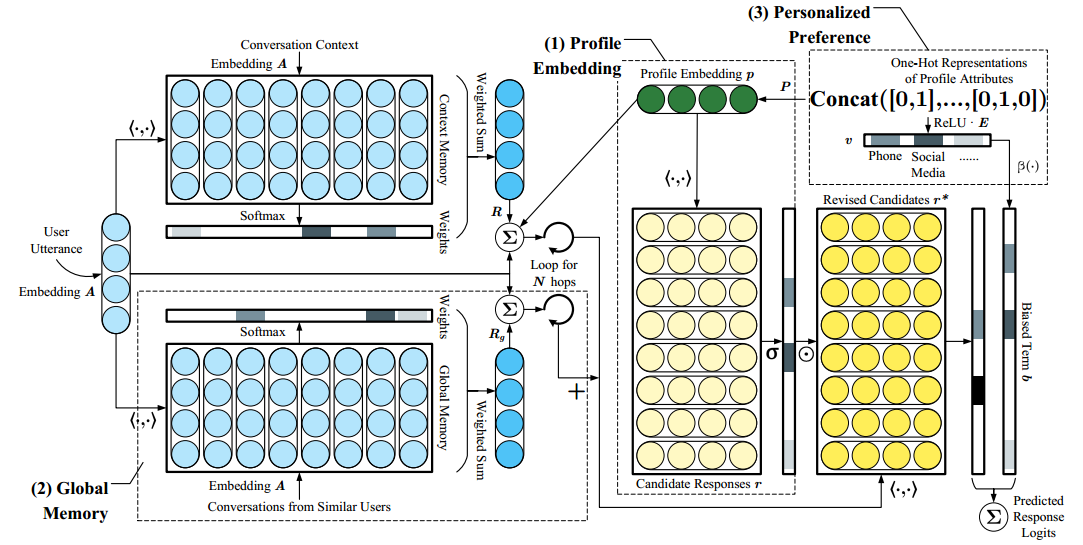
profile model
user embedding的计算
对话语料中用$n$个键值对属性$\lbrace(k_i,v_i)\rbrace_{i=1}^n$来描述用户画像。第$i$个属性被表示为one-hot vector $a_i \in R^{d_i}$,其中$d_i$表示第$i$个属性$k_i$可能的取值个数。则总的用户画像的one-hot表示为$$\hat{a} = concat(a_1,a_2,…,a_n)$$ 有$\hat{a}\in R^{d_p}$,其中$d_p = \sum_{i=1}^nd_i$
进一步将用户画像表示为分布式向量$$p = P\hat{a}$$ 其中$P$可以看作是embedding table。
将$p$结合到对话模型
将user embedding $p$结合到模型中的两个地方。
- 结合到多跳机制的query更新公式中。query对于context memory的读取和预测概率的生成起着重要作用。 $$q_{i+1} = q_i + o_i + p$$
- 根据user embedding对候选句子的向量表示进行修改。 $$r_i^* = \sigma(p^\top r_i) r_i$$
global memory
除了context memory外,模型还有一个memory用来储存相似用户的对话历史。本文中将相似用户定义为有相同的属性值的用户。global memory的读取方式与context memory的读取方式相同。最后将两部分的query结合起来:$$q^+ = q + q^g$$
