【来源】ICJAI2018
【链接】https://arxiv.org/abs/1706.02861
【数据集】http://coai.cs.tsinghua.edu.cn/hml/dataset/#AssignPersonality
【代码】未公布
这篇论文是清华大学黄民烈教授组的2017年的工作,2018年发表在IJCAI。
论文简介
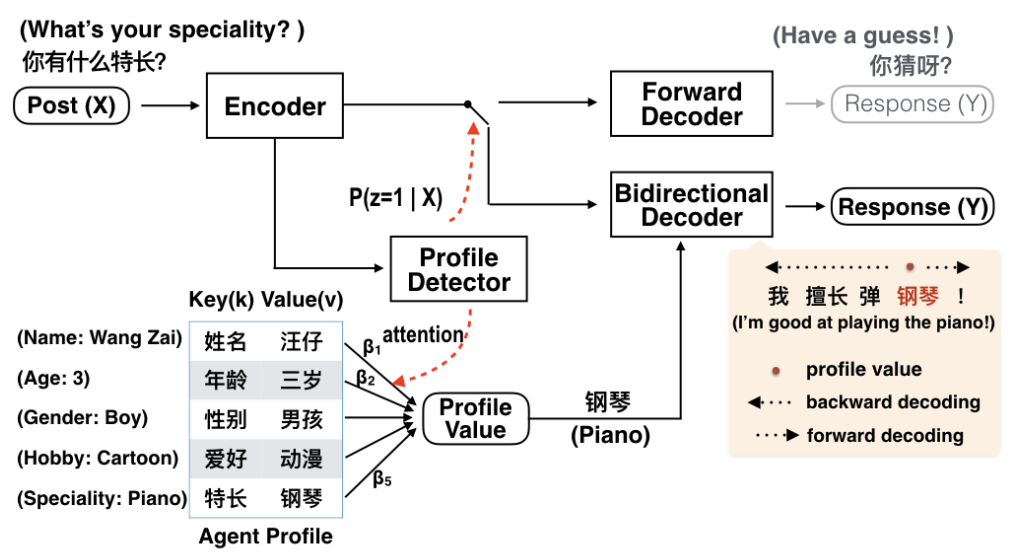
论文的研究内容是赋予对话系统以个性化信息(personality/profile)来生成具有一致性的回复。具体来说,对话语料中用键值对属性值来描述用户画像。对话系统先使用一个profile detector来检测生成回复时是否使用个性化信息。如果要使用,从所有的键值对属性用户画像中选择一个键值对来生成回复。采用一个bidirectional decoder来生成回复,让键值对出现在生成的回复中。进一步地,为了提高bidirectional decoder的性能,采用了position detector来检测键值对在回复中的位置。
模型结构
论文提出的对话模型包括了三个重要模块。profile detector检测是否使用用户画像并选择一个键值对属性。bidirectional decoder根据选中的键值对属性来生成回复。position detector检测键值对属性值在回复中出现的位置。
任务定义
给定post $X = \lbrace{x_1,x_2,…,x_n}\rbrace$以及描述用户个性化信息的键值对属性$\lbrace{<k_i,v_i>|i=1,2,…,K}\rbrace$,目标是生成有一致性的回复$Y = \lbrace{y_1,y_2,…,y_m}\rbrace$。
生成过程可以定义为: $$P(Y|X,\lbrace<k_i,v_i>\rbrace) = P(z=0|X) \cdot P^{fr}(Y|X) + P(z=1|X) \cdot P^{bi}(Y|X,\lbrace<k_i,v_i>\rbrace)$$
encoder
采用GRU将post $X = \lbrace{x_1,x_2,…,x_n}\rbrace$编码为$\lbrace{h_1,h_2,…,h_n}\rbrace$。GRU的更新公式如下:$$h_t = GRU(h_{t-1},x_t)$$
profile detector
作用有两个。一是检测是否使用profile,二是如果要使用,选择一个特定的键值对属性$<key,value>$来生成回复。
第一个作用,是否使用profile是在有标签数据上训练的二元分类器$P(z|X)$,计算方式如下:$$P(z|X) = P(z|\tilde{h}) = \sigma(W_p\tilde{h})$$ $$\tilde{h} = \sum_{j}h_j$$ 第二个作用,选择一个特定的键值对属性。生成一个在所有键值对上的概率分布:$$\beta_i=MLP([\tilde{h},k_i,v_i])=softmax(W\cdot [\tilde{h},k_i,v_i])$$其中$W$是可训练的模型参数,$\tilde{h}$是post的表示。则取概率最大的键值对作为选中的键值对:$$\tilde{v} = argmax_i(\beta_i)$$ 进一步地,bidirectional decoder的解码过程可以定义为:$$P^{bi}(Y|X,<\lbrace{k_i,v_i}\rbrace>) = P^{bi}(Y|X,\tilde{v})$$
bidirectional decoder
让选中的键值对属性值$\tilde{v}$出现在生成的回复中:$Y = (Y^b,\tilde{v},Y^f) = (y_1^b,…,y_{t-1}^b,\tilde{v},y_{t+1}^f,…,y_m^f)$。backward deocder生成$Y^b$,forward decoder生成$Y^f$。 解码过程可以定义为$$P^{bi}(Y|X,\tilde{v}) = P^{b}(Y^b|X,\tilde{v}) * P^f(Y^f|Y^b,X,\tilde{v})$$ $$P^{b}(Y^b|X,\tilde{v}) = \prod_{j=t-1}^{1} P^b(y^b_j|y^b_{<j},X,\tilde{v})$$ $$P^{f}(Y^f|Y^b,X,\tilde{v}) = \prod_{j=t+1}^{m}P^f(y_j^f|y_{<j}^f,Y^b,X,\tilde{v})$$ 具体地,生成一个word的概率分布为:$$P^b(y^b_j|y^b_{<j},X,\tilde{v}) \propto MLP([s_j^b;y^b_{j+1};c_j^b])$$ $$P^f(y_j^f|y_{<j}^f,Y^b,X,\tilde{v}) \propto MLP([s_j^f;y_{j-1}^f;c_j^f])$$ 注意区分backWard decoder与forward decoder的差别,分别是逆序和顺序的,一个输入的是$y^b_{j+1}$,而另一个是$y^f_{j-1}$。$s_j^{*},{*} \in \lbrace{f,b}\rbrace$ 是相应decoder的隐藏状态,$c_j^{*}$为相应的context vector。更新方式如下:$$s_j^{*} = GRU(s_{j+l}^{*}, [y_{j+l}^{*},c_j^{*}])$$ $$c_j^* = \sum_{t=1}^n\alpha_{j,t}^{*}h_t$$ $$\alpha_{j,t} \propto MLP([s_{j+l}^{*},h_t])$$ 对于backWard decoder,有$* = b,l = 1$,而对于forward decoder,有$* = f,l = -1$。
position detector
为了检测属性值$v$在回复中出现的位置,在训练阶段,检测哪个词可以被profile中的属性值代替。也就是估计概率:$P(j|y_1y_2…y_m,<k,v>),j\in[1,m]$,这个概率分布的意义是词$y_j$可以被属性值$v$替换的可能性大小。这里采用最大化$y_j$与属性值$v$之间的余弦相似度:$$P(j|Y,<k,v>) \propto cos({y_j},{v})$$
