【来源】AAAI2020
【链接】https://arxiv.org/abs/1911.04700
【代码】未公布
这篇论文是清华大学黄民烈教授组发表在AAAI2020的论文。
论文简介
论文主要研究个性化的对话系统。论文中提出了“persona-dense”和“persona-sparse”的概念。
- persona-dense: 像
Persona-Chat数据集中,在收集语料的过程中,对话人要求在有限的轮数内交流彼此的个性化信息,对话内容是与persona是密切相关的。 - persona-sparse:而在现实的对话中,只有少数的对话与persona是相关的,大多数的对话往往是与persona不相关的。直接在真实对话的语料上训练和微调模型,可能会让模型学习到大多数与persona无关的对话,而把少数与persona相关的对话当作是语料中的噪声。
为了解决这个问题,对话模型应该学习到哪些对话是与persona相关的,哪些对话是与persona不相关的。
论文采用了基于encoder-decoder框架的transformer模型。预训练的方法在许多NLP任务上取得了好的效果,论文提出用预训练的语言模型参数来初始化encoder和decoder。将attribute embedding添加到了encoder的输入;用了attention route机制来建模dialogue history,target persona和previous tokens这三种不同的特征;另外,用了dynamic weight predictor来控制这三种不同的特征在解码生成回复时起到不同程度的作用。
模型结构
任务可以描述为:给定对话历史$C$和回复者的target persona $T$,要求生成流畅的回复$Y$。 $$Y = argmax_{Y^{‘}}P(Y^{‘}|C,T)$$ 其中persona $T$由一系列属性来描述,$T = {t_1,t_2,…,t_N}$;每个属性用键值对来表示:$t_i = <k_i,v_i>$。对话历史扩展了说话人的信息,$C=\lbrace{(U_1,T_1),(U_2,T_2),…,(U_M,T_M)}\rbrace$
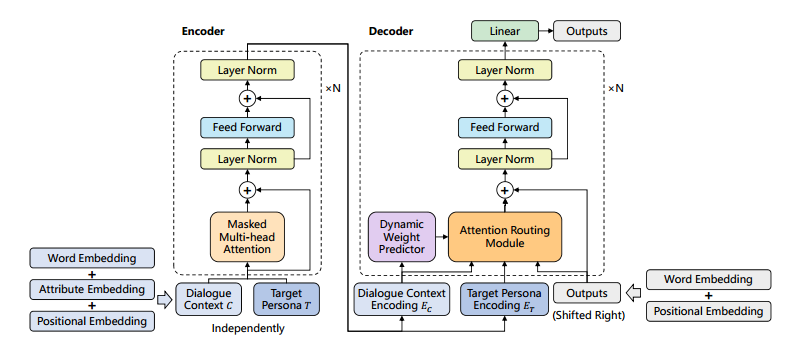
Encoding with Persona
模型的输入包括两个部分对话历史$C$和回复者的target persona $T$。
- 先说对话历史$C=\lbrace{(U_1,T_1),(U_2,T_2),…,(U_M,T_M)}\rbrace$的的编码,将所有的句子用特定的字符’_SPE’连接起来,并且将对话人$T_i$属性$t_i$映射为embedding表示。具体地,论文中的用户属性包括性别、地址、爱好三个。前两个的属性只有一个值,直接经过embedding层就可以了。爱好可能有多个值,经过embedding层后再取平均值即可。最终将word embedding + positional embedding + attribute embedding作为transformer encoder的输入。
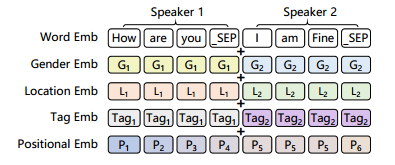 Fig.2. input representation of dialogue context
Fig.2. input representation of dialogue context - 至于回复者的target persona $T$的编码,将所有的键值对属性连接起来作为一个序列,经过embedding层,直接作为transformer encoder的输入。
Attention Routing
对于persona-sparse的对话语料,与persona无关的训练样例,在生成回复时不使用persona信息;与persona相关的训练样例,在生成回复时使用persona信息。论文为此设计了Attention routing模块来控制target persona $T$在生成回复时起到的作用。
具体地,将previous decoded tokens的表示$E_{prev}$作为attention的query,在对话历史$E_C$、回复者的target persona $E_T$和previous decoded tokens $E_{prev}$这三种特征上使用multi-head attention机制: $$O_T = MultiHead(E_{prev},E_T,E_T)$$ $$O_C = MultiHead(E_{prev},E_C,E_C)$$ $$O_{prev} = MultiHead(E_{prev},E_{prev},E_{prev})$$ 计算$O_T$和$O_C$时使用unmasked self-attention机制,计算$O_{prev}$时使用masked self-attention机制为避免decoder看到未来时刻的信息。
用一个persona weight $\alpha$把三个attention route $O_T,O_C,O_{prev}$结合起来:$$O_{merge} = \alpha O_T + (1-\alpha)O_C + O_C + O_{prev}$$ persona weight $\alpha$应该基于对话是否与persona有关,论文设计了dynamic weight predictor来预测$\alpha$。具体地,这个predictor是一个以对话历史$E_C$为输入的二元分类器$P_{\theta}(r|E_C)$:$$\alpha = P_{\theta}(r = 1|E_C)$$ 这个dynamic weight predictor的训练损失采用交叉熵函数:$$L_W(\theta) = -\sum_i r_i log P_{\theta}(r_i|E_C) + (1-r_i)log(1-P_{\theta}(r_i|E_C))$$
Pre-training and Fine-tuning
我们先在大规模的文本语料上预训练一个语言模型,最小化负对数似然函数:$$L_{LM}(\phi) = -\sum_ilog P_\phi(u_i|u_{i-k},…,u_{i-1})$$其中$\phi$是语言模型的参数,$k$是窗口大小。
接着用预训练好的语言模型的参数来初始化transformer模型的encoder和decoder,对于回复生成任务,最优化以下的目标函数:$$L_D(\phi) = -\sum_ilogP_{\phi}(u_i|u_{i-k},…,u_{i-1},E_C,E_T)$$
为了把预训练阶段和微调阶段联系起来,在微调阶段,也会在对话语料训练集上最小化语言模型的损失函数。也就是把语言模型的损失函数作为微调阶段的辅助损失函数。则微调阶段,模型总的损失函数为:$$L(\phi,\theta) = L_D(\phi) + \lambda_1L_{LM}(\phi) + \lambda_2L_W(\theta)$$
