【来源】ACL2019
【链接】https://www.aclweb.org/anthology/P19-1608.pdf
【代码】未公布
这篇论文是huggingface发表在ACL2019的短文。
论文简介
传统的有监督学习方法是:在特定的任务上,在有标签的数据集上,有监督地训练一个模型。有监督学习的局限在于许多NLP任务缺乏有标签的数据集,或者有标签数据集的规模比较小。迁移学习就派上用场了,迁移学习在许多NLP任务上取得了好的效果。迁移学习的思路是:先在大规模的未标注文本语料上无监督地预训练一个语言模型,再把预训练好的语言模型迁移到特定的任务上,对模型参数进行微调。
目前迁移学习的大部分研究集中在文本分类和NLU(natural language understanding)任务上,迁移学习应用在NLG(natural language generation)任务上的研究比较少。论文认为NLG任务可以分为两类:
- high entropy任务。例如story generation,chit-chat dialog。输入文本包含的信息有限,可能不包含生成输出文本所需要的信息。
- low entropy任务。例如文本摘要、机器翻译。特点是输入文本的信息量比较多,生成输出文本需要的信息包含在输入文本中。
论文主要研究了迁移学习在对话系统上的应用。
模型结构
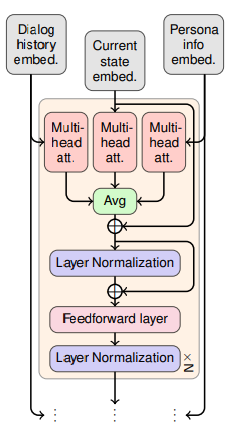
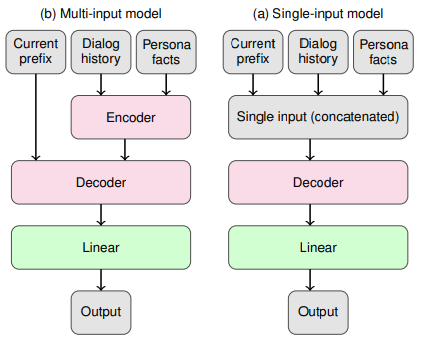
对话系统主要有三种输入:dialogue history,facts以及previous decoded tokens。论文研究单输入模型和多输入模型。单输入模型应用场景有限,主要关注下输入的部分。多输入模型基于encoder-decoder框架,关注下decoder部分的调整。
单输入模型
单输入模型把三种输入连接起来作为模型的输入。连接方式有三种:
- 用自然分隔符连接输入。论文中给每句对话添加双引号。
- 用空间分隔符连接。比如用’_SEP’把每个句子连接起来。
- 直接把句子连接起来,再用context-type embedding(CTE)来表示输入的类型。例如:$w_{CTE}^{info}$表示用户画像信息,$w_{CTE}^{p^1}$表示对话人1说的话,$w_{CTE}^{p^2}$表示对话人2说的话。
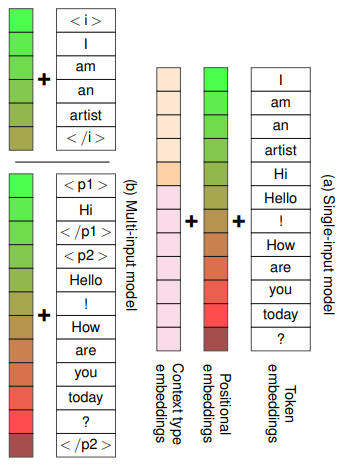 Fig.2. (a)单输入模型使用CTE方式的输入(b)多输入模型用起始分隔符连接的输入
Fig.2. (a)单输入模型使用CTE方式的输入(b)多输入模型用起始分隔符连接的输入
多输入模型
多输入模型基于encoder-decoder框架。用预训练的语言模型参数来初始化encoder和decoder。多输入模型的输入同样可以采用单输入模型的处理方式。将persona information和dialogue history分别送入encoder进行编码得到两个向量表示。重点在于decoder部分的调整。decoder的multi-head attention模块处理三种特征输入(personal information,dialogue history,previous decoded tokens),再把三者的结果取平均值即可。