Hadoop是一个开源框架,允许在跨计算机的分布式环境中来存储和处理数据。
Hadoop简介
Hadoop是一个开源框架,允许在跨计算机的分布式环境中来存储和处理数据。随着技术发展,人类每天都会产生海量数据,用单一的机器来存储和处理这些数据已经不能满足需求。而Hadoop允许在从单一的机器扩展到上千台机器,从而在跨计算机的分布式环境中来存储和处理大数据。
Hadoop的架构如下图所示: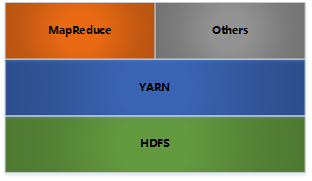
- HDFS: 分布式文件存储系统
- YARN: 分布式资源管理
- MapReduce: 分布式计算
- Others: 利用YARN的资源管理来实现其他的数据处理方式
HDFS
HDFS(Hadoop Distributed File System)是Hadoop应用主要的分布式文件系统。HDFS是基于“Master-Worker”架构的,一个HDFS集群由一个NameNode和多个DataNode组成。NameNode是一个中心服务器,管理文件系统的命名空间(NameSpace),管理文件系统的元数据(MataData),相当于是一个目录。DataNode负责存储实际的数据。
HDFS暴露了文件系统的命名空间,用户可以以文件的形式来存储数据。具体来看,一个文件被分为一个或者多个数据块(Block),这些数据块存储在一组DataNode上;每个数据库对应NameNode上的一条记录。NameNode执行文件系统的命名空间操作,比如打开、关闭、重命名文件或目录;它也负责数据库与DataNode之间的映射。DataNode负责处理文件系统客户端的读写请求,在NameNode的统一管理下来进行数据块的创建、删除和复制。
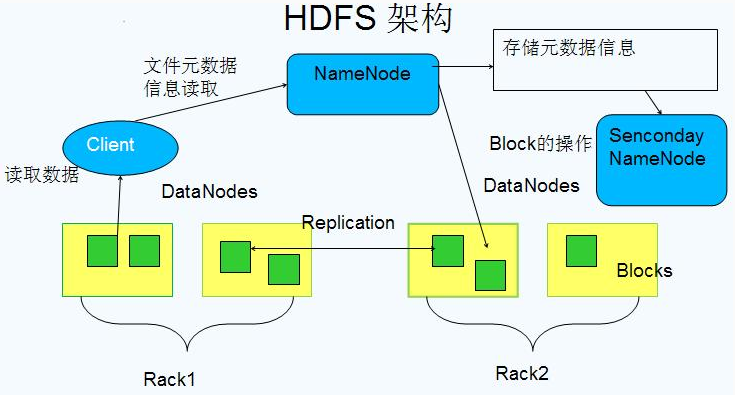
- Block
- 数据块block是基本存储单位,一般大小为64MB。
- 一个文件会被分成一个或多个数据块来存储。如果文件大小小于一个Block的大小,那么实际占用的空间为文件大小。
- Block是基本的读写单位,相当于磁盘的页,每次都会读写一个Block。
- 每个Block会被存储到多个机器,默认是3个。防止机器故障造成数据丢失。
- NameNode
- 存储文件的元数据,管理文件系统的命名空间。整个HDFS可存储文件的大小受限于NameNode的内存大小。
- 一个Block对应NameNode中的一条记录。
- NameNode失效后,整个HDFS就都失效了。要保证NameNode的可用性。
- DataNode
- 存储具体的block数据。
- 负责数据的读写操作和复制操作。
- DataNode启动时会向NameNode汇报当前存储的block信息,随后也会定时向NameNode汇报修改信息。
- DataNode之间会进行通信,复制block,保证数据的冗余性。
HDFS shell命令
Hadoop包含了一系列类shell命令,可以直接和HDFS或hadoop支持的其他文件系统进行直接的交互。hadoop fs -help可以列出所有的shell命令。这些shell命令支持大部分普通文件系统的操作,比如复制、删除文件、更改文件权限等。
调用文件系统shell命令应该采用hadoop fs <arg>的形式,所有的FS shell命令都使用URI路径作为参数。URI路径的格式是’scheme://authority/path’,对于HDFS文件系统,scheme是hdfs;对于本地文件系统,scheme是file。其中scheme参数和authority参数是可选的,省略的话会使用默认的参数scheme。
ls
使用方式:hadoop fs -ls <args>
如果是文件,会显示文件信息;如果是目录,会显示目录下所有的文件。test
使用方式:hadoop fs -test [edz] URI
选项:
-e 检查文件是否存在,如果存在返回0;
-z 检查文件是否是0字节,如果是返回0;
-d 如果路径是个目录,返回1,否则返回0
