信息检索的含义是非常广泛的,在学术界将其定义为:在海量数据中找到符合信息需要的文档或文本。信息检索可以按照操作规模分为三类:网页搜索、个人信息搜索、企业或特定领域的搜索。
- 网页搜索: 提供了给 存放在百万台电脑上的百亿篇文档的搜索服务。网页搜索特有的问题是 需要爬取收集建索引的海量文档,并且在海量文档尺度上建立高效的搜索系统。另外,还需要处理一些网页特有的问题,比如超链接的爆炸性增长。
- 个人信息搜索: 消费者客户端提供了信息搜索功能。比如个人邮件系统不仅可以搜索,还可以实现垃圾邮件分类。个人信息搜索特有的问题是 搜索服务启动、运行计算、磁盘占用的轻量级。
- 企业或特定领域搜索:这个规模是介于 网页搜索和个人信息搜索之间的。
词-文档矩阵(term-document matrix)
有一个需求,在《莎士比亚全集》中,我们要找到包含词”Brutus”、”Caesar”但不包含词”Calpurnia”的书。一种方式是从头到尾读一遍这些书,保留包含词”Brutus”、”Caesar”的书,排除掉包含词”Calpurnia”的书。对于计算机来说,找出包含某些词的文档 对应于linux系统下的grep操作。但实际情况中,我们需要的比grep操作更多:
- 在海量的数据上进行检索操作。
- 需要进行 更复杂的匹配操作。比如: 查询词”Brutus”接近 词”Caesar”的文档,这里接近 可以定义为在同一个句子内。
- 对搜索结果进行排序,我们希望 高质量的匹配文档排序更靠前。
避免每次query都进行线性检索(也就是从头到尾把文档都读一遍)的方法是:提前为每篇文档建立索引。假设我们为每篇文档 记录是否包含某个词,我们可以得到一个 二元词-文档关联矩阵(binary term-document incidence matrix),如图1所示。对于 词-文档关联矩阵,它的行向量表示对于某个词,这个词出现在了哪些文档中;它的列向量表示 对于某篇文档,这篇文档包含了哪些词。
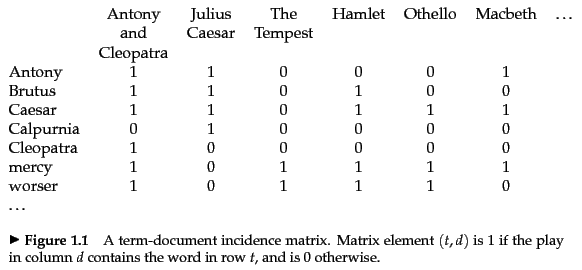
110100 AND 110111 AND NOT 010000 = 110100 AND 110111 AND 101111 = 100100
那么查询的结果就是《Antony and Cleopatra》和《Hamlet》。
布尔检索模型(boolean retrieval model)是可以把查询(query)表示成词的布尔表达式(词之间用与或非逻辑运算符连接)的一种信息检索模型,布尔检索模型把每篇文档看作是词袋(词的集合)。而 词-文档关联矩阵是进行布尔查询的基础。
倒排索引(inverted index)
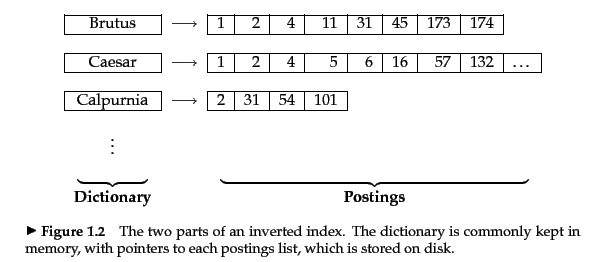
接下来我们考虑一种更现实的搜索场景。假设我们有 N = 1000,000篇文档(documents),我们在这个文档集合(collections)上进行检索。假设每篇文档有1000个词,每个词占用内存大约6字节,那么整个文档集合占用的内存约为6GB。另外,整个文档集合大约有 500,000个不同的词。这种情况下,构建一个 $500K \times 1M$ 的词-文档矩阵是不切实际的,这样的词-文档矩阵占用了太多的内存,并且这个矩阵是非常稀疏的(矩阵只有很少一部分元素是非零的)。更好的表示方法是只记录词出现在哪些文档中,这种想法是信息检索的一个重要概念:倒排索引(inverted index)。
图2展示了一个倒排索引的例子,我们维护一个词表(dictionary),对于每个词,对应一个包含这个词的文档列表。 每个词对应文档列表被称为”postings list”,所有文档列表的集合被称为”Postings”。
如何建立倒排索引
为了提高检索效率,缩短检索时间,我们需要提前构建好索引。构建倒排索引需要四步:
- 收集需要建立索引的文档;
- 对文本进行分词处理,将文档转换为词的列表;
- 对词进行语言学预处理,得到标准化的词。比如 $Friends \to friend; was \to is$
- 为包含每个词的文档建立倒排索引。倒排索引包含两个部分:dictionary 和postings。
图3左侧,我们为每篇文档分配一个唯一的文档号(docID),文档中的每个词对应它的文档号; 图3中间,按字母对词进行排序,图3右侧,按照词进行分组,合并文档号。这样就得到了倒排索引的dictionary 和 postings。dictionary不仅保存了每个词,还保存了其他一些统计信息(比如 包含每个词的文档数),这些统计信息可以提高 加权排序检索模型的搜索效率。每个词的postings list中保存了包含这个词的文档列表,也可以保存一些统计信息(比如这个词在每篇文档中的出现次数,出现的位置)。
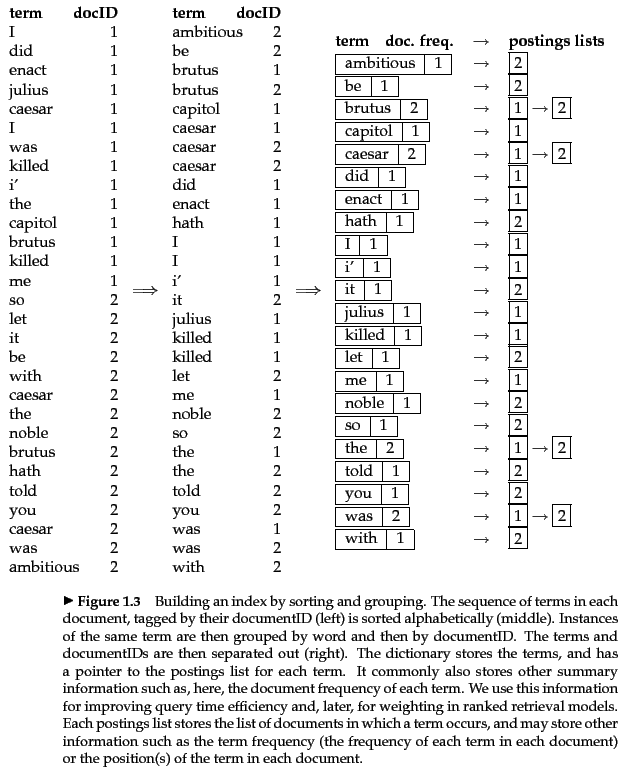
接下来讨论一下dictionary和 postings list的存储。dictionary保存在访问速度更快的内存中,postings list更大,通常保存在磁盘中。用什么数据结构来保存postings list呢?固定长度的数组比较浪费存储空间,因为高频词出现在更多的文档中,低频词则出现在很少的文档中。好的两种数据结构是 单链表 和 可变长度的数组。单链表的优点是方便进行postings list的更新操作,可以很快的插入新的docID。可变长度的数组 的优点是不需要存储单链表的指针,从而节省了磁盘空间;另外可变长度数组存储在连续的内存中从而提高了处理速度。
基于倒排索引进行boolean query
如何基于倒排索引来进行布尔查询呢?考虑最简单的联合查询Brutus AND Calpurnia。如图4所示,可以分为以下两步:
- 从dictionary中取出词
Brutus的postings list 和 词Calpurnia的postings list. - 取这两个postings list的交集。这个交集就是包含两个词的文档。

