文本表示是将文本中的字词进行数值化或向量化表示。文本表示是各种NLP任务的基础。如何将一篇文本用数学语言来表示呢?下面对不同的文本表示方法做一个归纳:
- 离散式表示(Discrete Representation):
- one-hot向量表示。
- tf-idf
- 分布式表示(Distributed Representation):
one-hot向量表示
先构建一个词汇表,词所在位置的值为1,其他值都是0。one-hot向量表示有两个缺点:
(1)维度灾难。one-hot向量表示的维度等于词汇表的大小,且向量过于稀疏而浪费内存。
(2)语义鸿沟。词汇表中任意两个词的one-hot向量表示都是正交的,不能通过余弦相似度方法来衡量两个词之间的相似性。
TF-IDF
TF-IDF计算一个词对与一篇文档的重要程度。如果一个词在一篇文档中出现的次数越多,那么这个词对这篇文档的重要性越大。$$TF词频 = \frac{一个词在文档中出现的次数}{这篇文档的总词数}$$另一方面,如果这个词出现在越多的文档中,说明这个词越常见,这个词包含的特征越少。$$IDF逆文档频率 = log({\frac{语料库中文档的数量}{包含这个词的文档数 + 1}})$$综合考虑这两个方面,将TF与IDF相乘作为这个词的tfidf值: $$TF-IDF = 词频TF \times 逆文档频率IDF$$
参考链接:TF-IDF算法
TextRank
TF-IDF算法从词的统计信息(词频、逆文档频率)出发,反映了一个词对一篇文档的重要程度。TFIDF并没有考虑到词与词之间的语义信息,而TextRank算法考虑到了词与词之间的语义关系,是一种基于图的关键词提取算法。另外,TFIDF需要一个语料库来计算词的逆文档频率,而TextRank算法脱离了语料库的背景,仅对单篇文档进行分析就可以提取关键词。
TextRank算法的核心思想是:通过词之间的相邻共现关系来构建网络,然后用PageRank算法来计算每个节点(词)的rank值,排序rank值即可得到关键词。
PageRank算法
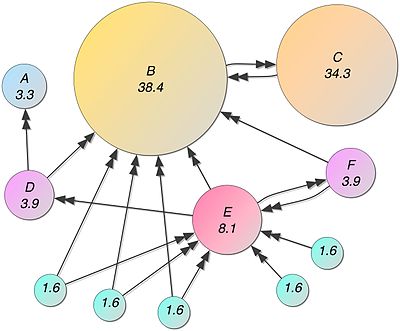
PageRank算法是Google创始人拉里$\cdot$佩奇和谢尔盖$\cdot$布林提出的一种网页排序的链接分析算法。基本思想有两条:
- 链接数量。一个网页有越多的入链,也就是被越多的其他网页所链接,那么这个网页的重要性越高。
- 链接质量。一个网页被一个越高权重的网页所链接,那么这个网页的重要性越高。
如果把网页看作是一个个节点,把网页之间的链接看作节点之间的有向边,那么可以得到一个有向图$G = (V,E)$。计算节点$V_i$的PR(pagerank)值的迭代公式为:$$PR(V_i) = (1-d) + d \times \sum_{V_j \in In(V_i)}\frac{PR(V_j)}{|Out(V_j)|}$$ $PR(V_i)$表示节点$V_i$的pagerank值;$In(V_i)$表示节点$V_i$入链集合;$Out(V_i)$表示节点$V_i$的出链集合;$d$表示damping factor,阻尼系数,一般设置为0.85,便于快速收敛。
src: https://en.wikipedia.org/wiki/PageRank
TextRank算法提取关键词
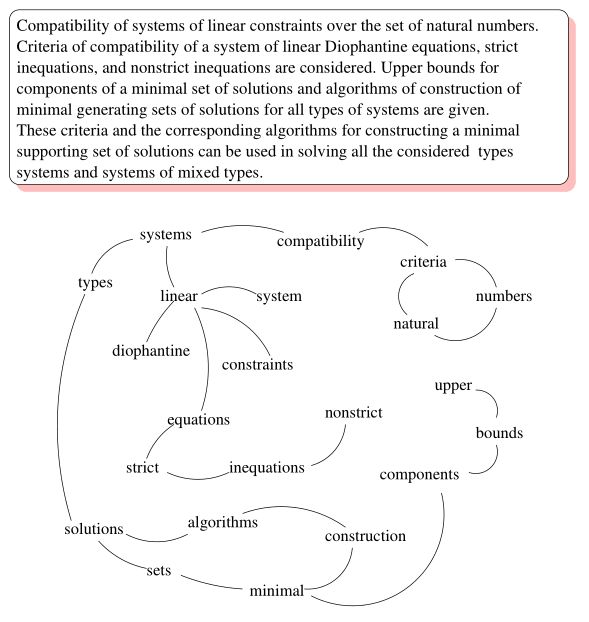
(1)文档$T$由多个句子组成$T = \lbrace{S_1, S_2, …, S_m}\rbrace$,对每个句子进行分词和词性标注,过滤停用词,只保留特定词性的词语(比如:名词、形容词、动词),第$i$个句子可表示为$S_i = \lbrace{w_{i,1}, w_{i,2}, …, w_{i,n_i}}\rbrace$。
(2)构建词图$G = (V,E)$,其中$V$为节点集合。对于每个句子$S_i = \lbrace{w_{i,1}, w_{i,2}, …, w_{i,n_i}}\rbrace$,给定一个长度为$K$的滑动窗口,当且仅当两个词在滑动窗口内共现时,两个词之间存在边。两个词之间边的权重为两个词的共现次数。
(3)随机初始化每个节点的rank值。
(4)根据textrank算法的迭代公式,迭代计算每个节点的rank值,直至收敛。
(5)按照节点的rank值倒序排列,排序靠前的候选词可以作为关键词。
src: https://www.cnblogs.com/en-heng/p/6626210.html
用textrank算法/TF-IDF算法 进行文本表示
我们可以将 文档中关键词的textrank值(或 tfidf值)作为向量来表示文本。得到两个文本的向量表示之后,就可以用余弦相似度等度量方法来计算两个文本之间的相似度。计算两个文本之间相似度的步骤如下:
(1)使用textrank算法(或 TF-IDF算法)来提取两个文本的关键词。
(2)将两个文本的关键词合并起来,计算每个文本中关键词的textrank值。
(3)生成两个文本各自的textrank值 向量表示。
(4)计算两个文本的余弦相似度,值越大,表示这两个文本越相似。
参考链接:
PageRank算法–从原理到实现
关键词提取算法TextRank
关键字提取算法TF-IDF和TextRank(python3)
关键词提取和摘要算法TextRank详解与实战
